



小室誠一
バベル翻訳大学院(USA) eTrans Technology Manager / Professor
毎年10月から11月にかけて、翻訳/機械翻訳のイベントがまとまって開催されるようになっています。今年も10月24日のJTF翻訳祭を皮切りに、いくつもイベントが開催されました。そのいくつかに参加するとともに、インターネット上で公開されている論文等に目を通して、現在の機械翻訳について、特に翻訳業界を取り巻く環境の変化についてまとめてみました。
■ニューラル機械翻訳が公開されて3年
Googleがニューラル機械翻訳を公開した、記念すべき2016年11月からすでに3年経ちました。今では、すっかり統計機械翻訳からニューラル機械翻訳へ移行した感があります。

さて、この3年間でニューラル機械翻訳にはどのような進展があったのでしょうか?
●2019年の機械翻訳
(1)ニューラル機械翻訳の手法が第2世代になった
技術的な話は省きますが、RNN (Recurrent Neural Network) 方式から TF (Transformer) 方式になって、Self-attentionと呼ばれる仕組みを取り入れることで、文内の遠い位置にある単語との関係をとらえることが可能になりました。
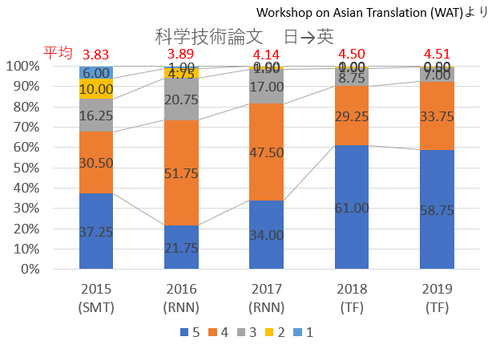
WAT2019 (The 6th Workshop on Asian Translation:アジア翻訳ワークショップ) の結果によると、科学技術論文の日英翻訳では、5段階評価で、平均4.51まで精度が上がっているとのことです。
(2)オープンソースのニューラル機械翻訳エンジンが利用可能になった
例えば、OpenNMT(http://opennmt.net/)を使えば、比較的簡単に独自のニューラル機械翻訳エンジンを作成できます。ということは、これからは、単に「機械翻訳」ではなく、どこで作成したエンジンなのかを特定しないと制度の比較ができないということになります。
(3)アダプテーション(カスタマイズ)によって翻訳精度の向上が図れる
特定分野の対訳データを追加して学習することにより、翻訳精度が大きく向上することが報告されています。
日本では、NICT(国立研究開発法人情報通信研究機構)が運用する「翻訳バンク」(https://h-bank.nict.go.jp/)が対訳データの集積を行っており、すでに、特許、医薬、金融・IRの分野で高精度の機械翻訳を構築しています。
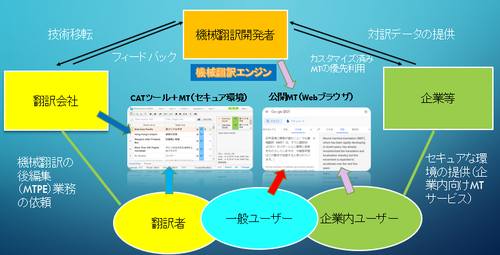
■機械翻訳はどのように利用されているか
現在、機械翻訳は様々な形で利用されています。ここでは、翻訳業界に絞り込んで見てみましょう。
もっともお馴染みなのは、Google翻訳のようなWebで公開されている機械翻訳サービスでしょう。最新のエンジンを無料で利用できるのですが、翻訳したデータは開発用に蓄積されてしまいますので、セキュリティの面からリスクがあります。手軽に使えるので一般ユーザには便利である一方、翻訳者が業務で利用するのは問題があります。また、企業でも社員がそのようなサービスを利用すると情報が漏洩することがあるので注意が必要です。
翻訳会社や企業は、翻訳者や社員にそのような一般公開された機械翻訳を「こっそり」利用されるのを防ぐために、セキュアな環境で利用できる環境を提供する方向に進んでいます。
例えば、企業向けの機械翻訳サービス「YarakuZen」(https://www.yarakuzen.com/ja/) や、翻訳会社が提供する翻訳者向けの、みんなの自動翻訳@KI (個人版)(https://www.k-intl.co.jp/minna-mt_personal)など、多くのサービスが登場しています。
■翻訳業界ではどのように機械翻訳に対応しているか
機械翻訳を使った翻訳サービスを行っている翻訳会社の報告で目立つのは、自ら進んで機械翻訳を導入しているというよりも、クライアントからの要望によって利用しているということです。
その要望には、当然、コストダウンと納期短縮が含まれています。最近の機械翻訳は飛躍的に精度が向上したのだから、それを使えば当然、翻訳料金が安くなり早くできるだろうということです。これらの要求はもっともなことではありますが、品質的には人手翻訳のレベルにはなりません。そこで翻訳と区別する意味で、MTPE(機械翻訳の後編集)サービスとして提案することになります。このサービスでは、クライアントとの条件のすり合わせが大切になってきます。
その一方で、すでにMTの利用が標準となっている分野もあります。以前からCATツールを活用してきたローカライズ翻訳の世界では、統計的機械翻訳(SMT)が実用化された頃から利用されています。そもそも、ルールベース機械翻訳が翻訳実務には利用できないとされ、翻訳メモリ(TM)ツールが開発されCATツールとして長年利用されてきた結果、膨大な翻訳メモリ(対訳コーパス)が蓄積されました。そのデータを統計処理してできたのがSMTとなります。SMTはCATツールに組み込まれ、翻訳メモリにマッチする文がない場合に、機械翻訳出力を挿入するという使い方をされるようになりました。日本でSMTがそれほど注目されなかったのは、SMTは対訳コーパスをフレーズに細分化してそれをつなぎ合わせる方式だったので、欧米言語と文構造の大きく異なる日本語との翻訳にはあまり向かなかったためです。それがニューラル機械翻訳になって、日本語がらみの翻訳でも流暢な文が出力されるようになって、現在では機械翻訳の利用が標準となっています。
3年前に機械翻訳に関するサービスとして期待された「ポストエディット」は、まだ、試行段階にあるようです。要するに、ポストエディットだけを取りだしたサービスにするのは難しいということです。機械翻訳の出力文といっても、現在のように誰でもアダプテーションできる時代になると、その品質は大きく異なります。使用するMT出力文にどれだけ手を入れなくてはならないか、その都度、評価する必要があります。そして、どの程度のレベルに仕上げるのかも協議しなければなりません。これには、編集作業だけでなくコンサルティング含めたサービスを提供することが求められるでしょう。
さらに、ポストエディタ―の確保も難しい問題です。理想的にはベテランの翻訳者に担当してもらえれば良いのですが、報酬や待遇の点でほとんど無理ではないかというのが共通の認識です。その結果、新人翻訳者が担当する機会が多くなりますが、ポストエディットと翻訳では必要とされるスキルが異なるので、翻訳者としてのスキルアップを期待しても、翻訳力が強化されることはほとんどないでしょう。
■ニューラル機械翻訳の問題点はまだ解決していない
ニューラル機械翻訳の問題点は初期の頃から指摘されていましたが、まだ、本質的な解決はされていません。ニューラルネットワークシステム自体がブラックボックスになっているのが原因かもしれません。
* 訳抜け、湧き出しがある。過不足のない出力になるように制御できない。
* 低頻度語、専門用語、固有名詞などに弱い。用語の管理(訳語の統一)が難しい。
* 長い文に弱い。これは、ニューラル機械翻訳に限らず、どの方式でも同様。
ルールベース機械翻訳の場合は、文法ルールと辞書を手掛かりにしてボトムアップで訳文を作成していく方式で、曲がりなりにも構文解析、品詞解析、意味素性など、意味を理解しようと悪戦苦闘している姿がありましたが、コーパスベースの機械翻訳では、文の意味などはまったく無視して、ひたすら文字の置き換えをする方式となっています。このまま、開発が進んでも、言語学不在のシステムとしての本質は変わらないでしょう。ということは、必ず人間が介在して、原文の意味が正しく訳出されているかどうかチェックしなければならないということです。
■機械翻訳は今度どうなるか
●ニューラル機械翻訳の精度はまだまだ向上する
多くの研究が発表され、翻訳エンジンが急速に改良されています。NMTもすでに第2世代になっています。そろそろまた大きな飛躍が見られるかもしれません。
また、データ蓄積の機運が高まっており、アダプテーションにより、特定分野の翻訳精度が多いに向上することが見込まれます。
●2極分化が進む
すでに、標準的に利用されている分野があり、その範囲も広がっていくと思われます。まだ、ポストエディットが必要な段階ですが、修正したデータを追加学習することにより、いずれポストエディットは必要なくなるでしょう。
その一方で、完成度の高い訳文が必要な場合、人手翻訳が適切であると再認識されてきています。機械翻訳の出力文をいくらブラッシュアップしても、人手翻訳のレベルにすることは難しいのです。
●翻訳会社/翻訳者としてどう向き合うか
まず、機械翻訳の動向を注視することが大切です。数多くの研究が発表され、開発のスピードが速まっています。常に、新しい情報に目を向けておく必要があります。
機械翻訳の実用化に応じて翻訳の需要も変化します。これまでなかったような種類の翻訳案件が発生することも考えられます。いつでも適切なソリューションを提供できるようにしておくことが重要です。
それには、新しい生産方法に対処できる人材を教育・確保する必要があります。翻訳者としても、従来の生産方法だけにこだわらず、常に、新しいテクノロジーを取り入れていく姿勢が望ましいでしょう。
■おわりに
機械翻訳と人間の翻訳とはまったく別のもの。
機械翻訳の生成するものは翻訳ではなく「出力結果」である。
「語られた(書いてある)言語や文章の内容を、他の言語で言い直すこと」(新明解国語辞典)という一般的な定義に従えば、機械翻訳が内容を理解することができるようになるまでは、翻訳者の仕事がなくなることはないでしょう。